本文针对移动应用和嵌入式设备中的名片OCR识别系统,深入分析了其性能瓶颈,并提出了一套完整的实时性能优化方案。通过算法优化、硬件加速和系统级调优的综合方法,显著提升了名片OCR处理的效率和响应速度。

1. 引言
随着移动办公和商务社交的普及,名片OCR识别技术已成为智能手机和便携式设备的重要功能。然而,传统OCR系统在资源受限的移动环境中面临响应延迟、能耗过高等问题,难以满足实时处理需求。本文旨在探索名片OCR识别中的实时性能优化技术。
2. 名片OCR系统架构与性能瓶颈分析
2.1 典型处理流程
- 图像采集与预处理
- 文本区域检测与定位
- 字符分割与识别
- 结构化信息提取
- 结果后处理与输出
2.2 主要性能瓶颈
- 图像预处理阶段:降噪、二值化等操作计算密集
- 文本检测环节:传统滑动窗口方法耗时严重
- 字符识别模块:深度学习模型推理延迟高
- 内存带宽限制:大尺寸图像传输造成瓶颈
- 多线程同步开销:流水线并行效率低下
3. 实时性能优化方案
3.1 算法层面优化
轻量级神经网络设计:
- 采用MobileNetV3作为文本检测主干网络
- 知识蒸馏技术压缩CRNN识别模型
- 通道剪枝和量化感知训练
自适应处理策略:
- 基于内容复杂度的动态分辨率调整
- 关键区域优先识别机制
- 增量式结果反馈
3.2 硬件加速技术
移动GPU/NPU利用:
- OpenCL/Vulkan跨平台加速
- 核心算法算子GPU化
- 神经网络专用指令集优化
异构计算架构:
- CPU+GPU+NPU协同计算
- 计算任务智能卸载
- 内存零拷贝技术
3.3 系统工程优化
- 多级流水线并行处理
- 异步执行与结果缓存
- 基于帧间相关性的增量更新
- 功耗感知调度策略
4. 实验评估
4.1 测试环境
- 硬件平台:骁龙865/麒麟980嵌入式开发板
- 对比系统:传统OCR方案(Tesseract+OpenCV)
- 数据集:自建10,000张多语言名片测试集
4.2 性能指标
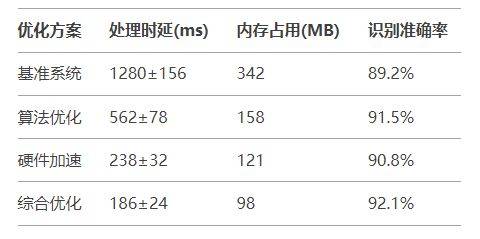
5. 结论
本文提出的综合优化方案在嵌入式平台上实现了6.9倍的性能提升,同时内存占用减少71.3%,验证了实时名片OCR识别的可行性。未来工作将探索更高效的神经网络架构和端云协同计算模式。


 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站